
Frontends
Two schemes for extracting the acoustic features from a speech signal have been standardized by ETSI as output of the work inside the Aurora group. The intention is an application in a DSR (distributed speech recognition) scenario where the acoustic features are extracted in any type of terminal in a fixed or mobile network and are transmitted to a recognition system at a remote position somewhere in the network. Because of this each standard contains not only the feature extraction, but also a scheme for compressing and decompressing the features. This allows the transmission of the compressed features at a data rate of 4800 Bit/s.First Standard
The scheme that was standardized first, is based on an “usual” cepstral analysis as applied in a lot of recognition systems. The block diagram below gives a rough overview about the analysis technique.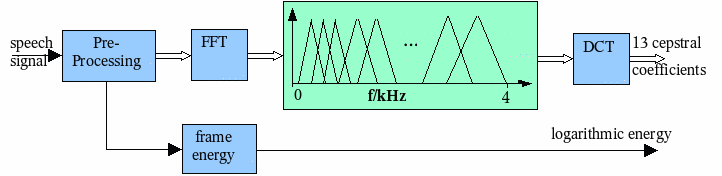
- The preprocessing consists of a DC offset compensation and a preemphasis. Furthermore the signal is split into overlapping frames by multiplying the samples with a 25 ms Hamming window. The window is shifted by 10 ms for the short-term analysis corresponding to a frame rate of 100 Hz.
- The logarithm of the energy is calculated for each frame from the samples after the DC offset compensation. This parameter is taken as one component of the feature vector. The Hamming weighted samples are transformed to the spectral domain with means of a FFT.
- The FFT magnitude spectrum is taken as input to a Mel filterbank with 23 channels.
- The logarithm of the 23 Mel spectral coefficients is taken as input to a further DCT. The output of the DCT are 13 cepstral coefficients (C0 – C12) that are used as further components of the feature vector.
Second Standard
The second advanced feature extraction scheme has been designed to compensate some distortion effects that are present in almost all applications of speech recognition. Therefore the analysis scheme of the first front-end has been extended by two further processing blocks to achieve higher recognition performance in situations with noise in the background and with unknown modifications of the frequency characteristics due to e.g. the microphone or the transmission channel. A block diagram is shown in the figure below. This includes also the compression scheme that was not shown in the block diagram of the first standard.
- A two stage Wiener filter is applied on the speech signal as processing step to reduce background noise. The filter characteristics is estimated in the frequency domain where the filtering itself is done in the time domain after transforming back the estimated filter characteristics to the time domain. A further SNR dependent waveform processing is applied on the filtered signal.
- A VAD (voice activity detection) flag is created as part of the noise reduction process for each frame. This flag is included as part of the data stream at the output so that it could be used for excluding frames from the recognition process at the recognition stage.
- The noise reduced signal is taken as input to a cepstral analysis scheme that is almost identical with the scheme of the first standard. The output of this processing block are again 13 cepstral coefficients (including C0) and 1 logarithmic energy coefficient per frame at a frame rate of 100 Hz.
- The cepstral coefficients (without C0) are processed with a blind equalization scheme to compensate the influence of unknown frequency characteristics. This blind equalization is based on the comparison to a flat spectrum and the application of the LMS algorithm.
- Finally the 13 cepstral coefficients and the energy coefficient are compressed with the means of a split vector codebook. The resulting data stream, that contains also the VAD flag, can be taken for a circuit data or a packet data transmission.
A detailed algorithmic and mathematical description of both standards as well as a C code implementation is available from ETSI. The first standard has the document number ES 201108 and the second standard ES 202050.